Custom Indexing Framework
Sui는 transaction, 이벤트, object 변경 등과 같은 풍부하고 복잡한 데이터를 생성한다. Sui가 이 데이터에 접근하기 위한 표준 API를 제공하더라도, 많은 애플리케이션은 특정 이벤트 추적, 분석 집계, 대시보드 구축, 특화된 데이터베이스 생성과 같은 워크플로를 위해 맞춤형 데이터 처리 기능을 필요로 한다.
Custom indexer는 필요한 특정 블록체인 데이터를 추출하고 변환하며 저장하는 데 사용할 수 있다. Sui API를 반복적으로 조회하거나 복잡한 필터링 로직을 구축하는 대신, 원시 블록체인 데이터를 한 번 처리하여 원하는 형식으로 저장한다.
Custom indexer를 생성하기 위해 sui-indexer-alt-framework Rust 프레임워크를 사용할 수 있다. 이 프레임워크는 데이터 수집, 처리, 저장을 위한 프로덕션 레벨의 컴포넌트를 제공하는 동시에 인덱싱 로직에 대한 완전한 제어권을 제공한다.
Custom indexing 프레임워크를 활용하는 것은 다음과 같은 프로젝트 및 사례에 필요하다:
- DEX 거래량을 추적
- NFT 컬렉션 활동을 모니터링
- 분석 대시보드를 구축
- 특화된 검색 인덱스를 생성
- 크로스체인 브리지 데이터를 집계
Framework architecture
큰 흐름에서 보면, 인덱싱 프레임워크는 사전 정의된 데이터 소스에서 사용 가능한 최신 체크포인트를 지속적으로 폴링하고 해당 checkpoint 데이터를 파이프라인의 처리 로직으로 스트리밍하는 스트리밍 파이프라인이다.
Sui의 체크포인트는 일관된 블록체인 상태 스냅샷을 나타내는 transaction batch이다. 각 체크포인트에는 완전한 transaction 세부 정보, events, object changes, 실행 결과가 보장된 순서로 포함된다. 체크포인트에 대한 더 많은 정보는 Life of a Transaction을 참조한다.
Detailed architecture
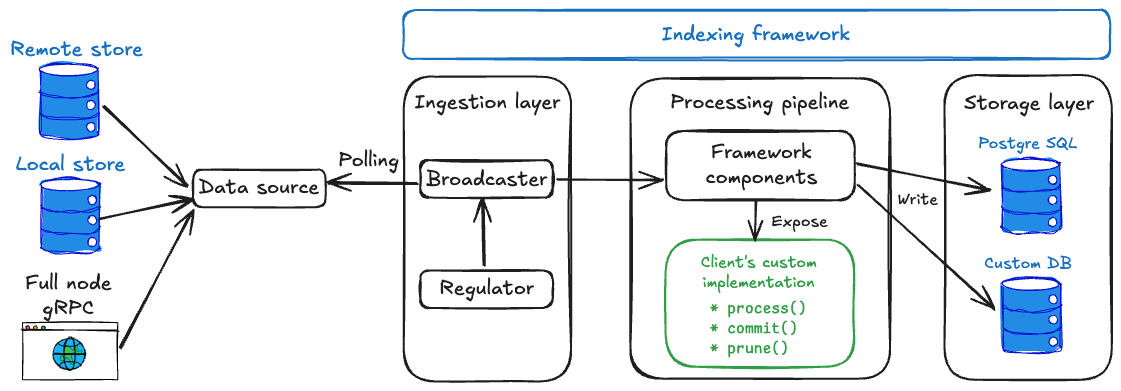
다음 다이어그램은 custom indexer 아키텍처를 자세히 보여준다.
Data sources
Checkpoint 데이터는 다음을 포함한 다양한 데이터 소스에서 얻는다:
- Remote stores는
https://checkpoints.mainnet.sui.io와 같은 공개 checkpoint 스토어에 연결한다. 이는 자체 인프라를 운영하지 않고 시작하는 가장 간단한 방법이다. - Local files는 로컬 Sui 풀 노드가 덤프한 체크포인트 파일을 처리할 수 있게 하여 가장 낮은 지연을 제공하지만, 이러한 파일은 자동으로 정리되지 않으므로 테스트 용도로만 사용�해야 한다.
- RPC endpoints는 Sui 풀 노드 RPC 엔드포인트에 직접 연결할 수 있게 하여, 제어 가능한 신뢰할 수 있는 데이터 소스를 사용하거나 remote store가 없는 네트워크(예: Devnet)에 연결할 수 있게 한다. 인덱싱 프레임워크는 유연성을 극대화하기 위해 다수의 데이터 소스를 지원한다.
Ingestion layer
인덱싱 프레임워크는 checkpoint 데이터를 신뢰성 있게 가져오고 분배하는 복잡한 작업을 처리하는 수집 레이어를 관리한다. Broadcaster는 데이터 소스로부터 체크포인트를 수신하고 이를 병렬로 실행되는 여러 처리 파이프라인에 효율적으로 분배한다. 이는 서로 다른 데이터 처리 워크플로를 동시에 실행하는 인덱서에 필수적이다.
Regulator는 어떤 체크포인트를 가져올지 Broadcaster에 지시하여 데이터 흐름 속도를 제어하는 스마트 코디네이터 역할을 한다. 이는 subscriber들이 보고하는 high watermark에 의해 백프레셔를 받아 Broadcaster가 과도하게 가져오지 않도록 한다.
Processing layer
인덱싱 프레임워크와 사용자의 코드가 모두 처리 레이어를 관리하며, 이 레이어에서 커스텀 로직이 프레임워크와 통합된다. 파이프라인 프레임워크 컴포넌트는 checkpoint 처리를 오케스트레이션하고 처리량을 극대화하기 위한 동시성을 관리하며 진행 상황 추적과 데이터 일관성 보장을 위한 watermark를 유지하고 수집부터 저장까지 전체 데이터 흐름을 조정하므로 시스템의 핵심이다. 프레임워크 컴포넌트는 선택한 파이프라인 유형에 따라 조정된다:
- Sequential pipelines는 batch 기능을 갖춘 순차 처리에 최적화된 다른 컴포넌트를 사용한다.
- Concurrent pipelines는 고처리량의 순서 비보장 처리를 위해
Collector,Committer,Pruner와 같은 컴포넌트를 사용한다.
그 후 프레임워크는 데이터 처리 로직을 정의하기 위해 구현해야 하는 특정 인터페이스를 노출한다. 일반적인 API에는 다음이 포함된다:
process(): 원시 checkpoint 데이터(transactions, 이벤트, object changes)를 원하는 데이터베이스 행으로 변환한다. 여기에서 유의미한 정보를 추출하고 관련 데이터를 필터링하며 저장을 위한 형식으로 정렬한다.commit(): 적절한 transaction 처리를 통해 가공된 데이터를 데이터베이스에 저장한다. 프레임워크는 효율적인 대량 작업을 위해 가공된 데이터 batch와 함께 이를 호출한다.prune(): 보존 정책에 따라 오래된 데이터를 정리한다(옵션). 최근 데이터를 보존하면서 오래된 레코드를 제거하여 데이터베이스 크기 관리를 돕는다.
순차 및 동시 파이프라인 유형과 그 트레이드오프는 Pipeline Architecture에 자세히 설명되어 있다.
Details
CheckpointData struct
#[derive(Clone, Debug, Serialize, Deserialize)]
pub struct CheckpointData {
pub checkpoint_summary: CertifiedCheckpointSummary,
pub checkpoint_contents: CheckpointContents,
pub transactions: Vec<CheckpointTransaction>,
}
Storage layer
인덱싱 프레임워크는 유연한 스토리지 레이어를 통해 데이터베이스 작업을 추상화한다. PostgreSQL은 Diesel ORM을 사용하는 내장 지원을 제공하여 프로덕션 레벨의 데이터베이스 작업, 커넥션 풀링, 마이그레이션, watermark 관리를 즉시 제공한다. 커스텀 데이터베이스 구현의 경우 프레임워크의 스토리지 인터페이스를 구현하여 문서 저장을 위한 MongoDB 또는 분석을 위한 ClickHouse 등 어떤 데이터베이스도 사용할 수 있다.
Single program, multiple threads
사용자의 인덱서는 여러 개의 조정된 백그라운드 작업(스레드)을 가진 하나의 실행 가능한 프로그램으로 동작한다. 수집 레이어는 새로운 체크포인트를 폴링하는 동안 처리 파이프라인은 데이터를 변환하고 저장하며 - 이 모든 작업은 동일한 프로세스 내에서 수행된다.
Related links
The sui-indexer-alt-framework provides two distinct pipeline architectures. Understand the differences between the sequential and concurrent pipelines that the sui-indexer-alt-framework provides to decide which best suits your project needs.
The life of a transaction on the Sui network has some differences compared to those from other blockchains.
Establishing a custom indexer helps improve latency, allows pruning the data of your Sui full node, and provides efficient assemblage of checkpoint data.